Contexto
Sistemas antifraude e de prevenção à lavagem de dinheiro (PLD) são amplamente utilizados no setor financeiro para mitigar riscos operacionais, regulatórios e reputacionais. Com o crescimento do volume transacional, modelos de Machine Learning tornaram-se componentes centrais desses sistemas. Nesse contexto, o papel do modelo não é decidir isoladamente, mas gerar scores de risco confiáveis que sirvam de base para políticas claras de decisão, revisão humana e auditoria. O valor do Machine Learning está na capacidade de produzir sinais consistentes, explicáveis e rastreáveis ao longo do tempo.
Problema
Na prática, muitos modelos de risco são avaliados com divisões aleatórias de dados, métricas genéricas e pouca atenção ao impacto operacional dos erros. Isso pode gerar uma percepção inflada de desempenho e decisões frágeis quando o modelo é colocado em uso. Sem uma separação explícita entre o score produzido pelo modelo e a política de decisão aplicada, bons resultados estatísticos nem sempre se traduzem em ações consistentes, justificáveis e auditáveis, especialmente em contextos regulados como AML e compliance.
Solução
Resultados
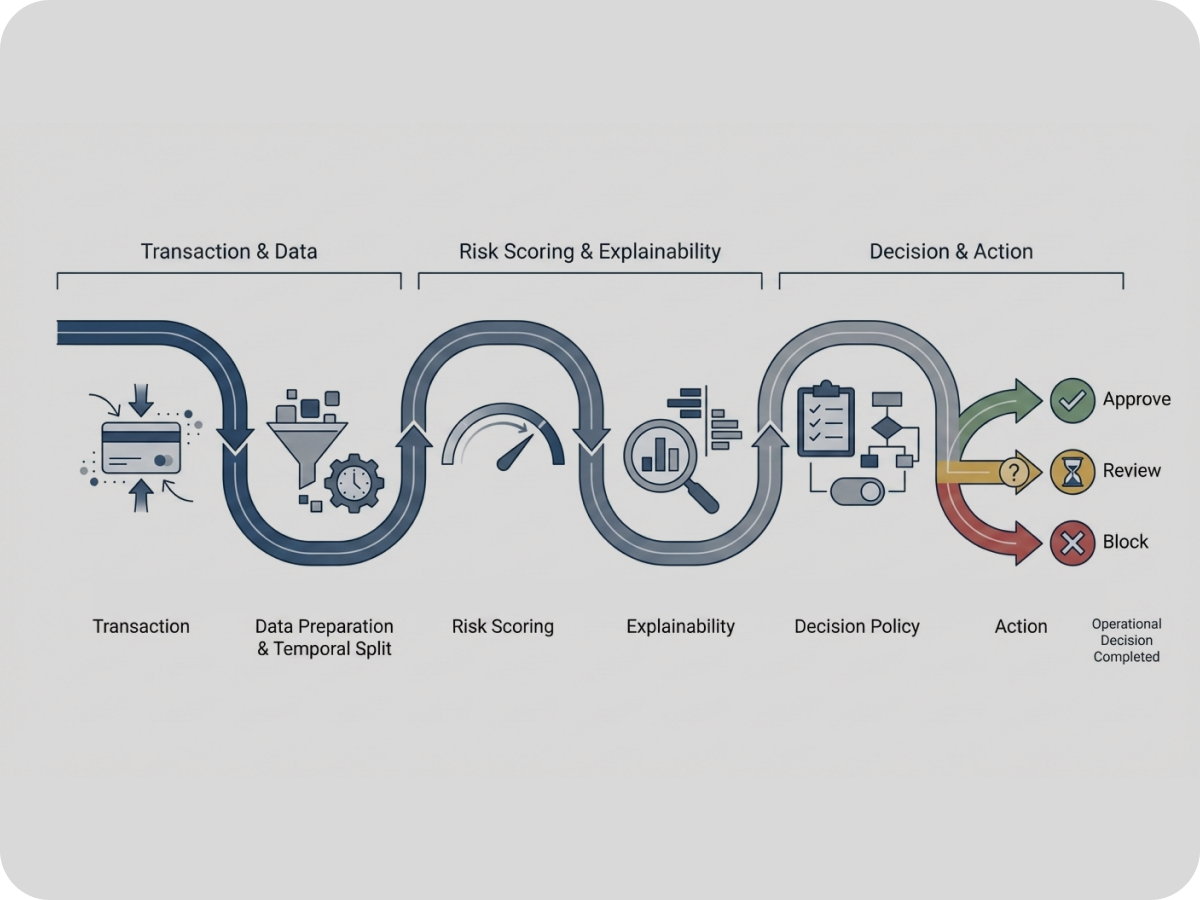
Pipeline de risk scoring com avaliação temporal explícita e métricas alinhadas a problemas reais de risco.
Geração de scores interpretáveis e comparáveis, utilizados como insumo para políticas de decisão.
Separação clara entre previsão do modelo, política de decisão e revisão humana.
Demonstração prática de como modelos de risco podem atuar como suporte estruturado à decisão em contextos antifraude e AML.
Por trás da solução
Acesse o repositório no GitHub para explorar o código, os dados e a organização analítica que estruturam esta prova de conceito (PoC).
Ver código no GitHubExplore outras soluções
Explore outras provas de conceito (PoCs) do portfólio e veja como diferentes problemas de negócio podem ser abordados com dados.
Ver outros projetos