Contexto
Organizações utilizam cada vez mais dados externos para apoiar análises, decisões operacionais e monitoramento de cenários. Esses dados geralmente vêm de APIs públicas, serviços de terceiros ou fontes abertas, em formatos brutos, heterogêneos e com pouca padronização. Sem um pipeline estruturado, a coleta desses dados tende a gerar arquivos isolados, difíceis de validar, reaproveitar ou evoluir. O desafio não está apenas em obter os dados, mas em transformá-los em ativos organizados, confiáveis e prontos para consumo analítico ao longo do tempo.
Problema
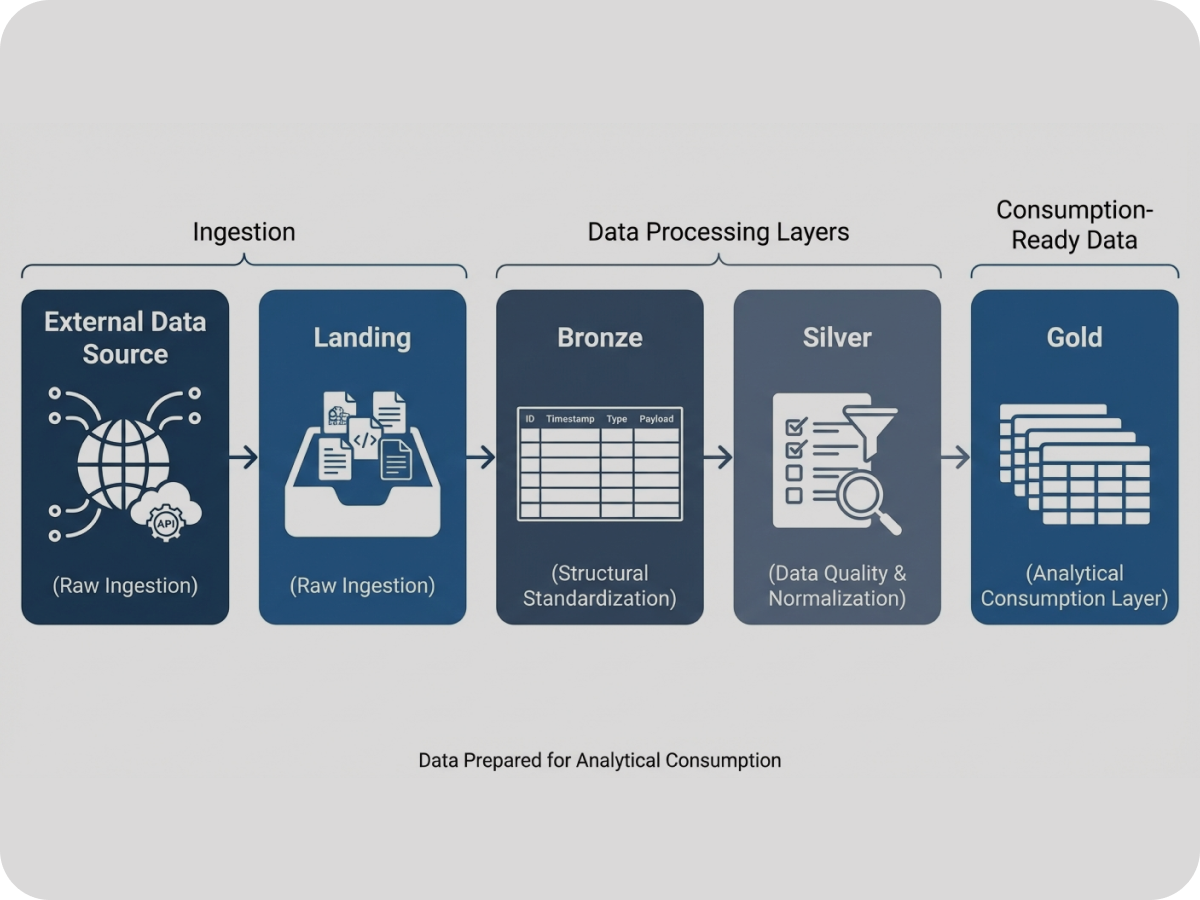
Na prática, muitos fluxos de ingestão de dados externos são implementados de forma pontual, sem separação clara de etapas, controle de qualidade ou rastreabilidade das execuções. Isso dificulta responder perguntas básicas, como: de onde veio esse dado, quando foi coletado, quais transformações foram aplicadas e se ele está apto para uso analítico. O desafio desta prova de conceito foi construir um pipeline capaz de tratar dados externos de forma estruturada, com camadas bem definidas, execução previsível e dados prontos para consumo analítico, sem depender de soluções complexas ou específicas de negócio.
Solução
Resultados
Pipeline end-to-end funcional para ingestão e organização de dados externos
Separação clara de camadas analíticas, permitindo rastreabilidade e evolução controlada dos dados.
Dados estruturados e persistidos em formato analítico, prontos para consumo em consultas e análises.
Demonstração prática de como transformar dados externos brutos em ativos reutilizáveis.
Por trás da solução
Acesse o repositório no GitHub para explorar o código, os dados e a organização analítica que estruturam esta prova de conceito (PoC).
Ver código no GitHubExplore outras soluções
Explore outras provas de conceito (PoCs) do portfólio e veja como diferentes problemas de negócio podem ser abordados com dados.
Ver outros projetos